
Today, I'm going to review the paper for this CVPR 2023, Vid2Avatar.
"Vid2Avatar: 3D Avatar Reconstruction from Videos in the Wild via Self-supervised Scene Decomposition"
- ETH Zürich, CVPR 2023, Project Page, Paper
Summary
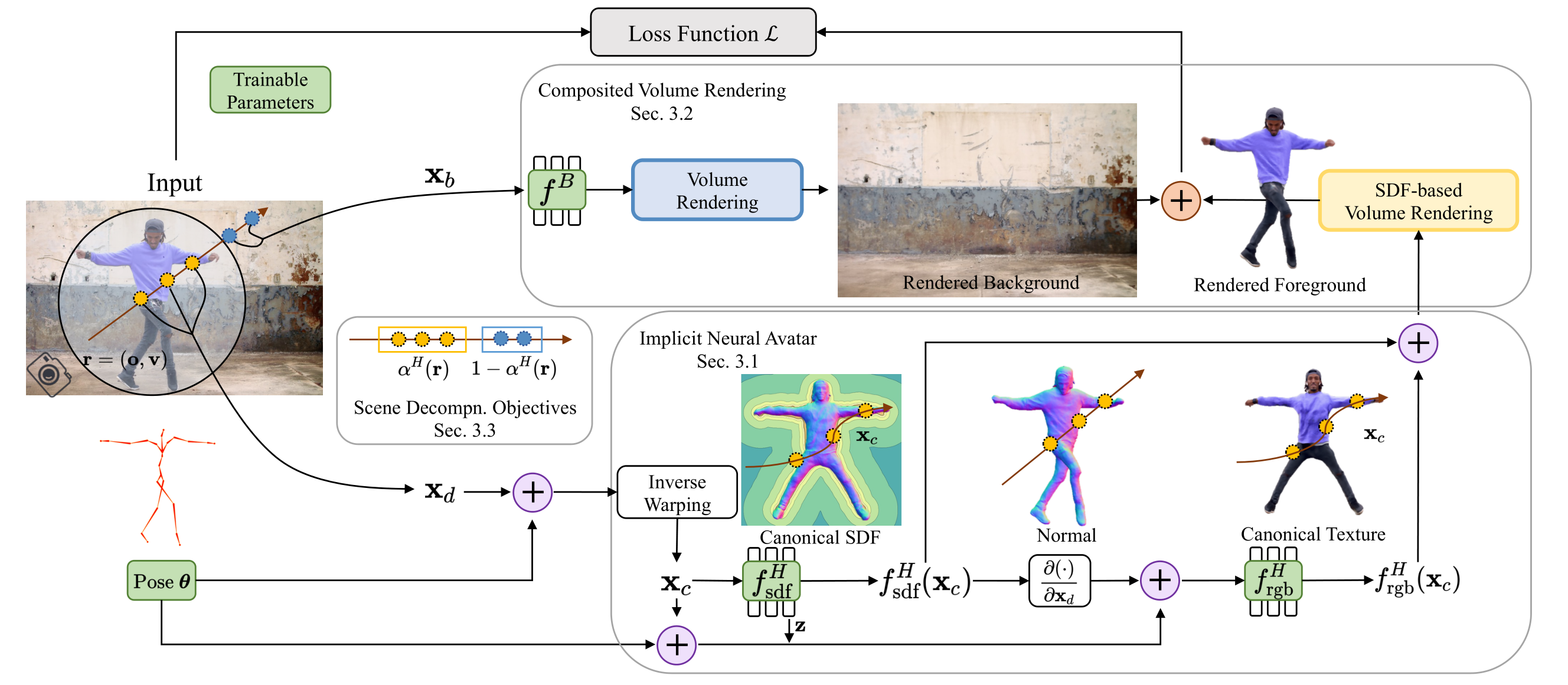
- casting the segmentation and surface as a joint 3d optimization problem
- external segmentation model X
- spherical space -> sample points are divided into in and out of the sphere
- inner space points -> canonical SDF -> resampling the points by making use of surface information -> canonical texture -> render RGB
- outer space points (randomly sampled) -> SDF (static scene, background) -> combined with dynamic foreground(human)